Hadoop व्यवस्थापक जिम्मेदारियाँ
Hadoop व्यवस्थापक जिम्मेदारियों पर यह ब्लॉग Hadoop प्रशासन के दायरे पर चर्चा करता है। Hadoop के एडमिनिस्ट्रेटर जॉब्स उच्च माँग में हैं इसलिए Hadoop अभी सीखें!

Hadoop व्यवस्थापक जिम्मेदारियों पर यह ब्लॉग Hadoop प्रशासन के दायरे पर चर्चा करता है। Hadoop के एडमिनिस्ट्रेटर जॉब्स उच्च माँग में हैं इसलिए Hadoop अभी सीखें!
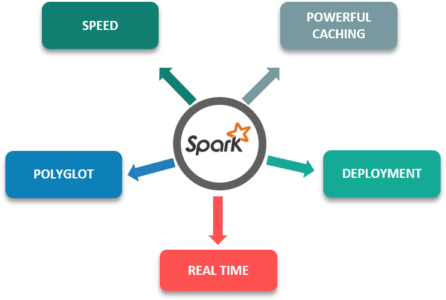
अपाचे स्पार्क बड़े डेटा प्रोसेसिंग में एक महान विकास के रूप में आया है।
Apache Hadoop 2.x में Hadoop 1.x पर महत्वपूर्ण सुधार शामिल हैं। यह ब्लॉग Hadoop 2.0 क्लस्टर आर्किटेक्चर फेडरेशन और इसके घटकों के बारे में बात करता है।
यह जॉब ट्रैकर के उपयोग के लिए एक अंतर्दृष्टि देता है
Apache Pig में कई पूर्वनिर्धारित कार्य हैं। पोस्ट में अपाचे सुअर में UDF को रोकने के स्पष्ट चरण शामिल हैं। यहां कोड जावा में लिखे गए हैं और इसके लिए पिग लाइब्रेरी की आवश्यकता है
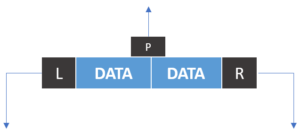
HBase संग्रहण वास्तुकला में कई घटक शामिल हैं। आइए इन घटकों के कार्यों को देखें और जानें कि डेटा कैसे लिखा जा रहा है।
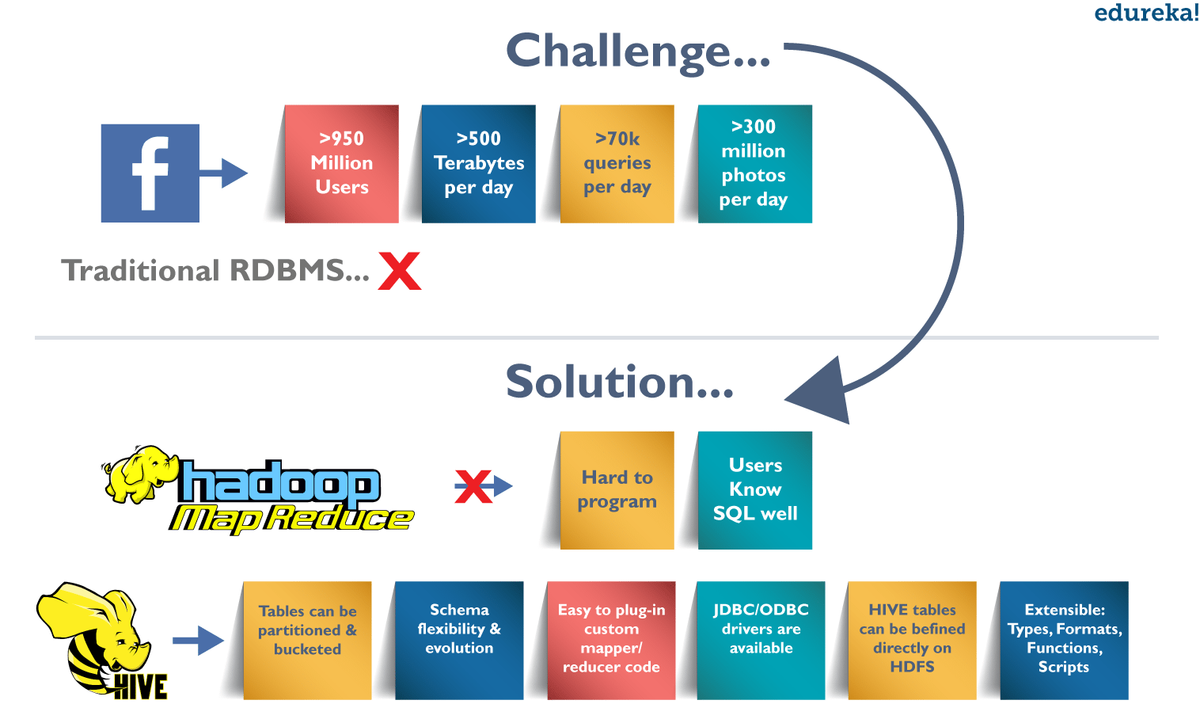
अपाचे हाइव एक डेटा वेयरहाउसिंग पैकेज है जो हडोप के शीर्ष पर बनाया गया है और इसका उपयोग डेटा विश्लेषण के लिए किया जाता है। हाइव उन उपयोगकर्ताओं की ओर लक्षित है जो एसक्यूएल के साथ सहज हैं।
शीर्ष कंपनियों द्वारा बड़े पैमाने पर हडोप के साथ अपाचे स्पार्क का कार्यान्वयन इसे वास्तविक समय प्रसंस्करण के लिए सफलता और इसकी क्षमता को इंगित करता है।
NameNode उच्च उपलब्धता Hadoop 2.0 की सबसे महत्वपूर्ण विशेषताओं में से एक है NameNode उच्च उपलब्धता Quorum जर्नल प्रबंधक के साथ सक्रिय और स्टैंडबाय NameNodes के बीच संपादित लॉग साझा करने के लिए उपयोग की जाती है।
Hadoop डेवलपर जॉब जिम्मेदारियों में कई कार्य शामिल होते हैं। जॉब जिम्मेदारियां आपके डोमेन / सेक्टर पर निर्भर करती हैं। यह भूमिका एक सॉफ्टवेयर डेवलपर के समान है
Hive डेटा मॉडल में निम्नलिखित घटक होते हैं जैसे डेटाबेस, टेबल्स, पार्टीशन और बकेट या क्लस्टर्स। ये इंटेगर, फ्लोट्स, डबल्स और स्ट्रिंग्स जैसे आदिम प्रकारों का समर्थन करते हैं।
Hadoop 2.0 के बारे में इन 4 कारणों से Hadoop जॉब मार्केट के बारे में बात होती है और यह आपको नौकरी के बड़े अवसरों के लिए खुला बनाकर आपके करियर को गति देने में मदद कर सकता है।
इस ब्लॉग में, हम स्पार्क पर हाइव और यार्न के उदाहरण चलाएंगे। सबसे पहले, स्पार्क पर हाइव और यार्न का निर्माण करें और फिर आप स्पार्क पर हाइव और यार्न के उदाहरण चला सकते हैं।
इस ब्लॉग का उद्देश्य यह सीखना है कि SQL डेटाबेस से डेटा को HDFS में कैसे स्थानांतरित किया जाए, SQL डेटाबेस से NoSQL डेटाबेस में डेटा कैसे स्थानांतरित किया जाए।
Apache Hadoop (CCDH) के लिए Cloudera प्रमाणित डेवलपर किसी के करियर को बढ़ावा देने वाला है। यह पोस्ट लाभ, परीक्षा पैटर्न, अध्ययन गाइड और उपयोगी संदर्भों पर चर्चा करती है।
यह ब्लॉग एचडीएफएस उच्च उपलब्धता वास्तुकला का अवलोकन प्रदान करता है और सरल चरणों में एचडीएफएस उच्च उपलब्धता क्लस्टर को कैसे सेट और कॉन्फ़िगर किया जाए।
रियल-टाइम एनालिटिक्स की बात करें तो अपाचे काफ्का लोकप्रिय बनी हुई है। कैरियर के अवसरों और नौकरी की मांगों पर चर्चा करते हुए, कैरियर के दृष्टिकोण से इस पर एक नज़र डालते हैं।
अपाचे काफ्का उच्च-थ्रूपुट और स्केलेबल मैसेजिंग सिस्टम प्रदान करता है जो इसे वास्तविक समय के एनालिटिक्स में लोकप्रिय बनाता है। जानिए कैसे अपाचे काफ्का ट्यूटोरियल आपकी मदद कर सकता है
यह ब्लॉग पोस्ट पिग और उसके कार्यों में एक गहरा गोता है। आप जावा पर कोई निर्भरता के साथ सुअर का उपयोग करके हाडोप पर कैसे काम कर सकते हैं, इसका डेमो मिलेगा।
यह ब्लॉग Hadoop सीखने के लिए किसी और चीज की चर्चा करता है, Hadoop के लिए जावा अनिवार्य है और जवाब है कि क्या आपको Pig, Hive, HDFS पता है तो आपको Hadoop सीखने के लिए Java की आवश्यकता होगी।