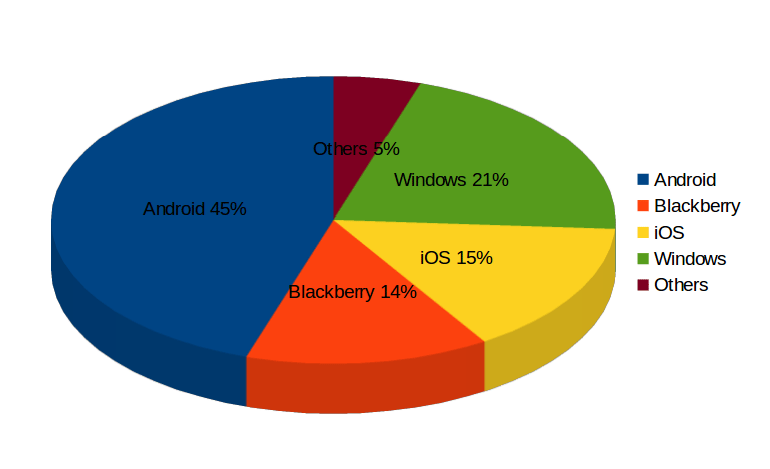
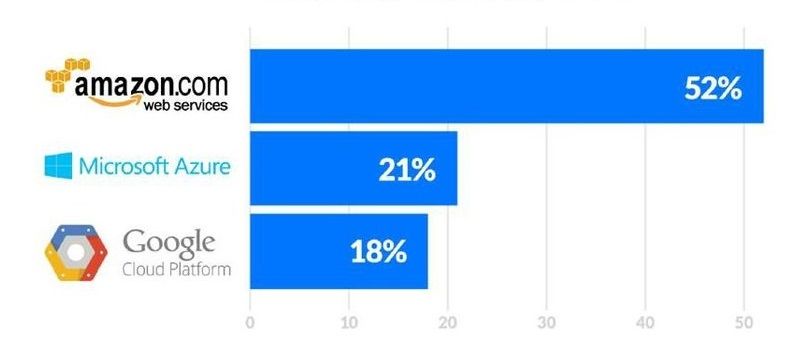
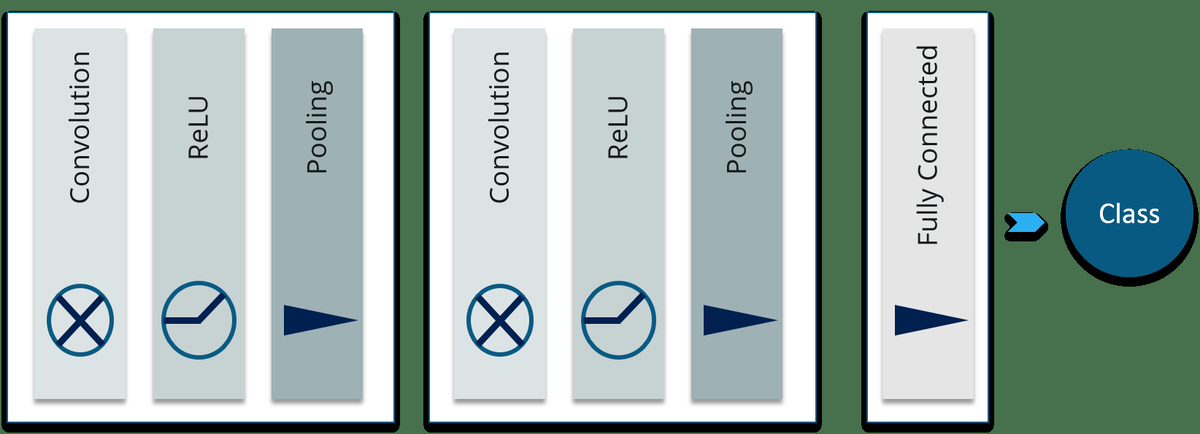
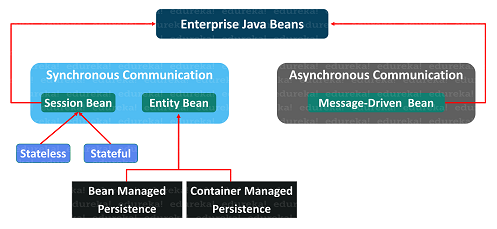
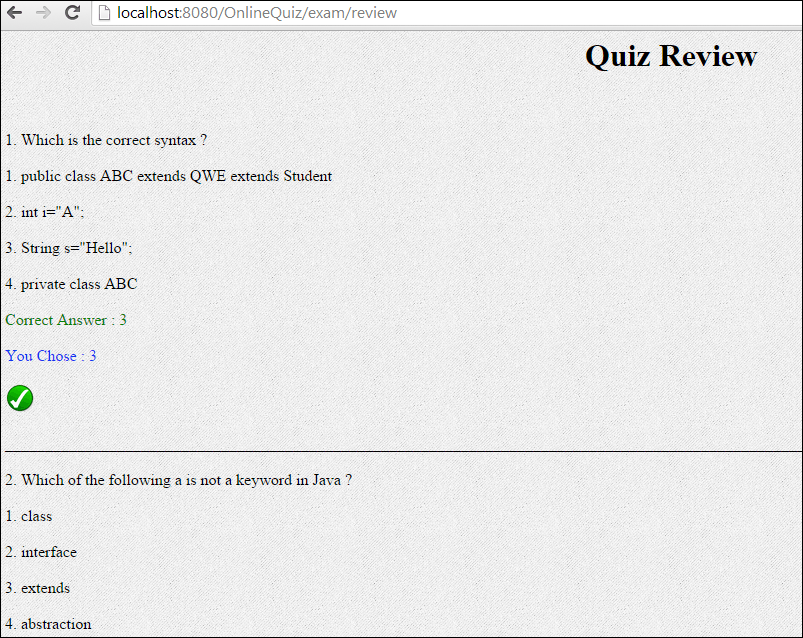
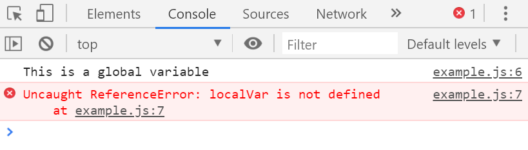
स्पार्क बनाम हाडोप: बेस्ट बिग डेटा फ्रेमवर्क कौन सा है?
यह ब्लॉग पोस्ट अपाचे स्पार्क बनाम हडूप के बारे में बोलती है। यह आपको एक विचार देगा कि विभिन्न परिदृश्यों में चुनने के लिए सही बिग डेटा फ्रेमवर्क कौन सा है।

यह ब्लॉग पोस्ट अपाचे स्पार्क बनाम हडूप के बारे में बोलती है। यह आपको एक विचार देगा कि विभिन्न परिदृश्यों में चुनने के लिए सही बिग डेटा फ्रेमवर्क कौन सा है।
यह ब्लॉग आपको यह समझने में मदद करता है कि ग्रहण आईडीई में स्केल एप्लिकेशन को चलाने के लिए चरण-दर-चरण निर्देशों के साथ sbteclipse प्लगइन कैसे स्थापित करें और सेट करें।
इस ब्लॉग पोस्ट में बताया गया है कि क्यों आपको Hadoop के बाद Apache Spark से शुरुआत करनी चाहिए और क्यों Hadoff में महारत हासिल करने के बाद Spark सीखना आपके करियर के लिए चमत्कार कर सकता है!
यह अपाचे ड्रिल ट्यूटोरियल आपको अपाचे ड्रिल क्वेरी इंजन, हैडोप, बिग डेटा और अपाचे स्पार्क के साथ उपयोग के साथ आरंभ करने के लिए आवश्यक सभी जानकारी देता है।
यह Spark Hadoop ब्लॉग बताता है कि आप सभी को Apache Spark CombByKey के बारे में जानना चाहिए। CombByKey पद्धति का उपयोग करके प्रति छात्र औसत अंक प्राप्त करें।
अपाचे फाल्कन Hadoop पारिस्थितिकी तंत्र के लिए एक नया डेटा प्रबंधन प्लेटफ़ॉर्म है जो हडूप समूहों पर फ़ीड प्रसंस्करण और फ़ीड प्रबंधन को सरल करता है। इसे सेट करना सीखें।
यह अपाचे स्पार्क ब्लॉग स्पार्क संचयकों के बारे में विस्तार से बताता है। उदाहरण के साथ स्पार्क संचायक उपयोग सीखें। स्पार्क संचायक Hadoop Mapreduce काउंटर की तरह हैं।
इस ब्लॉग में Apache Flink & Flink क्लस्टर सेट करने के बारे में सभी जानें। फ्लिंक रियल-टाइम और बैच प्रोसेसिंग का समर्थन करता है और बिग डेटा एनालिटिक्स के लिए बिग डेटा टेक्नोलॉजी होना चाहिए।
यह ब्लॉग पोस्ट प्रसारण चर के साथ वितरित कैशिंग की चर्चा करता है और आपको स्पार्क प्रोग्रामिंग में बड़े मूल्यों को कुशलतापूर्वक वितरित करने पर शुरू होता है।
क्लोडा द्वारा CCA और CCP प्रमाणपत्रों ने CCDH और CCSHB परीक्षाओं की जगह ले ली है। यह ब्लॉग आपको बताता है कि आपको नए प्रमाणपत्रों के बारे में जानने की आवश्यकता है।
यह ब्लॉग पोस्ट स्पार्क स्ट्रीमिंग में विंडोिंग के साथ स्टेटफुल ट्रांसफॉर्मेशन पर चर्चा करता है। राज्य-पूर्ण डी-स्ट्रीम का उपयोग करके बैचों के डेटा पर नज़र रखने के बारे में सभी जानें।
यह ब्लॉग पोस्ट स्पार्क स्ट्रीमिंग में स्टेटफुल ट्रांसफॉर्मेशन पर चर्चा करता है। एक Hadoop स्पार्क कैरियर के लिए संचयी ट्रैकिंग और अप-कौशल के बारे में सभी जानें।
Hadoop & Big Data Technologies हेल्थकेयर एनालिटिक्स में क्रांति ला रही हैं। हेल्थकेयर ब्लॉग में यह बड़ा डेटा चर्चा करता है कि बड़े डेटा एनालिटिक्स मेडिकल देखभाल को कैसे बढ़ा सकते हैं।
Hadoop स्ट्रीमिंग पर यह ब्लॉग पोस्ट बिग डेटा की विनम्र मात्रा को संसाधित करने के लिए पायथन में एक Hadoop MapReduce प्रोग्राम लिखना सीखने के लिए एक कदम-दर-चरण गाइड है।
बिग डेटा ट्यूटोरियल का यह ब्लॉग आपको बिग डेटा, इसकी विशेषताओं, अनुप्रयोगों के साथ-साथ बिग डेटा के साथ चुनौतियों का पूरा अवलोकन देता है।
यह एचडीएफएस ट्यूटोरियल ब्लॉग आपको एचडीएफएस या हडोप डिस्ट्रीब्यूटेड फाइल सिस्टम और इसकी विशेषताओं को समझने में मदद करेगा। आप इसके मूल घटकों को भी संक्षेप में बताएंगे।
इस स्प्लंक ट्यूटोरियल में स्प्लंक बनाम ईएलके बनाम सूमो लॉजिक के बीच के अंतर को समझें और निर्धारित करें कि इनमें से कौन सा उपकरण आपको सबसे अच्छा लगता है।
इस स्प्लंक यूज़ केस ब्लॉग में, आप समझेंगे कि डोमिनोज़ पिज़्ज़ा ने उपभोक्ता व्यवहार अंतर्दृष्टि प्राप्त करने के लिए स्पंक का उपयोग कैसे किया। और अपनी व्यापारिक रणनीतियों को तैयार करते हैं।
यह ट्यूटोरियल Hadoop क्लस्टर को स्थापित करने और इसे एक ही नोड पर कॉन्फ़िगर करने के लिए स्टेप गाइड बाय स्टेप गाइड है। सभी Hadoop स्थापना कदम CentOS मशीन के लिए हैं।
यह ब्लॉग विभिन्न HDFS कमांड जैसे fsck, copyFromLocal, expunge, cat इत्यादि के बारे में बात करता है जो कि Hadoop फाइल सिस्टम को प्रबंधित करने के लिए उपयोग किए जाते हैं।